Partial DILR Solving: Get 2 Marks From a Stuck Set
A practical CAT 2026 DILR guide to partial solving: tag each of a set's four questions as full-dependent or partial-eligible before you start, chase the partial deductions first, and bank 2-3 certain marks even when the full grid never resolves. Includes a dependency table, three worked extractions, and the common trap that turns recovered marks into negatives.
Eight minutes in, the grid is half-empty and the full solution is not coming. Two constraints fit, the third one keeps breaking the arrangement, and the clock is at 9:30. Most aspirants do one of two things here: keep grinding for the complete answer until time runs out, or abandon the set and move on with zero. Both leave marks on the table. The set is not fully solved, true. But partial DILR solving rests on a fact most people never test: the four questions in a set are not equally dependent on the complete arrangement, and some of them are already answerable from what you have.
See how a few recovered DILR marks shift your overall percentile and IIM call range.
Check My PercentileWhy a stuck set still has marks in it
A DILR set gives you one scenario and four questions. The instinct is to treat the scenario as a single lock: crack it, and all four open. But the questions sit at different depths. One might ask for the exact value assigned to every person. Another might ask only for the maximum possible value of one variable, or who definitely cannot sit at a particular position. These second questions need far fewer deductions to settle.
Here is the core idea behind partial deduction. When you stop solving at, say, 65 percent of the deductions, you have not failed. You have a stable partial state: some cells fixed, some ranges narrowed, some possibilities eliminated. A question that depends only on those fixed cells is now answerable with full certainty, regardless of whether the rest of the grid ever resolves. The marks are real, not probabilistic.
This matters because of how CAT 2026 DILR is scored. Each question is independent at +3 and -1. There is no bonus for solving the whole set and no penalty for answering only two of four. A set where you lock 2 questions and leave 2 blank earns +6 with zero risk. That is a strong return on a set that, by the conventional definition, you did not solve. The aspirants who clear the DILR sectional cut are rarely the ones who fully solve every set. They are the ones who never walk away from a hard set empty-handed.
Question dependency mapping
The technique has one move you make before you start solving: read all four questions and tag each by dependency. This costs about 40 seconds and changes how you spend the next ten minutes. You are no longer solving toward a single finish line. You are solving toward the cheapest marks first.
Tag each question as one of two types. Full-dependent questions need the complete arrangement: exact ranking of all entities, the precise value for each, or who occupies a specific named slot. Partial-eligible questions need only a slice: a minimum, a maximum, a count, a yes/no on whether something is possible, or a single heavily constrained value. The first sentence of the question usually tells you which it is. "How many" and "what is the maximum" lean partial. "Who is in seat 4" and "what is the complete order" lean full.
Once tagged, your solving order changes. Chase the deductions that open up your partial-eligible questions first, because those are the marks you keep even if the set never fully cracks. If the full solution arrives, you answer the full-dependent questions too and take all four. If it does not, you have already banked the recoverable ones. This is the heart of a working DILR elimination strategy: decide what is reachable, then reach for it in the right order. Rating the set before you commit, which the guide on how to rate a DILR set in 60 seconds walks through, tells you upfront whether you are likely to be doing full solving or partial extraction on this one.
The dependency map: needs full vs partial
Use this map as a reference for what each question type needs and what stays extractable when you are stuck. The pattern repeats across arrangements, distributions, tournaments, and grid puzzles.
| Question Asks For | Needs Full or Partial | Extractable When Stuck |
|---|---|---|
| Exact value for every entity | Full | No: leave blank unless the grid resolves |
| Complete ranking or order | Full | No: one open cell breaks the whole order |
| Maximum or minimum of one variable | Partial | Yes: once that variable's range is fixed |
| Count of entities meeting a condition | Partial | Often: if the condition's cells are settled |
| Who cannot occupy a position | Partial | Yes: elimination needs fewer deductions |
| Is a specific arrangement possible | Partial | Yes: one valid or invalid case settles it |
| Single value under heavy constraints | Partial | Yes: constraints often force it early |
| Who is in a specific named slot | Full | Sometimes: only if that slot locks early |
The right column is where your recovered marks come from. When a set goes hard, your eyes go straight to the partial-eligible rows and you ask one question: is the deduction this question needs already locked? If yes, answer it. The set is still incomplete, and you are still scoring.
Write a small F or P next to each question number on your rough sheet during the first read. F for full-dependent, P for partial-eligible. When the timer crosses your cap and panic starts, that tiny annotation is what tells you exactly where to look for the two marks instead of freezing or guessing.
Three worked extractions
Each example below shows a set that does not fully resolve, and the marks you take anyway. The numbers are illustrative, but the dependency logic is exactly what you apply in the exam.
Seven people in a row, three constraints fit, one stays loose
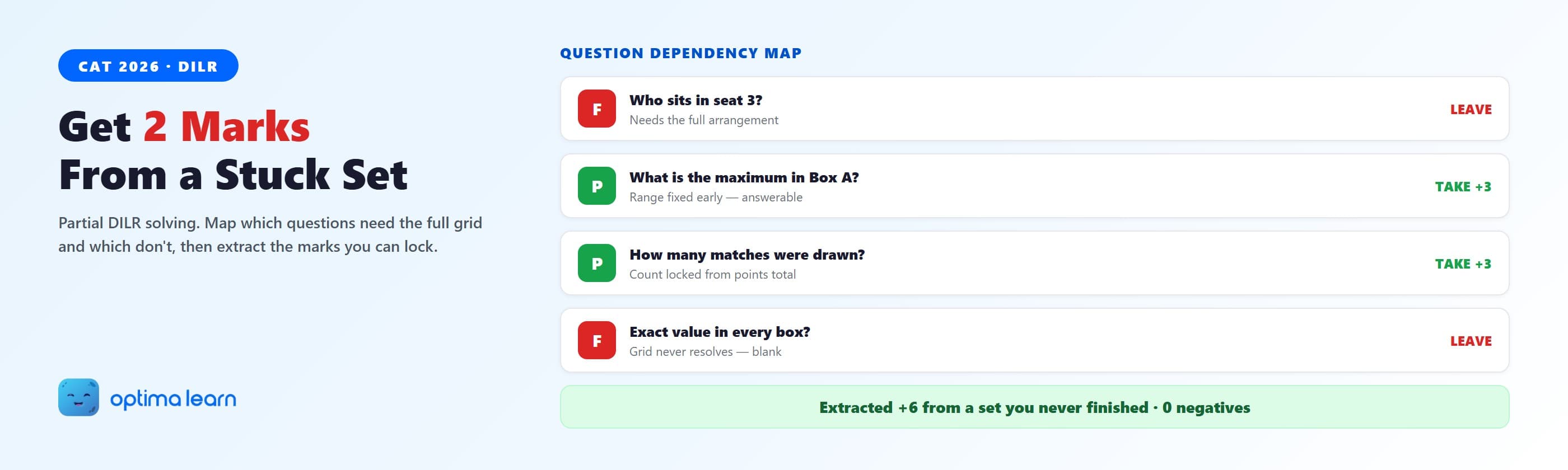
Seven friends sit in a row. You fix the two end seats and the middle from the first three clues. The fourth clue leaves two people swappable between seats 3 and 5, and you cannot break the tie with the information given in your time.
- Q1 (Full): "Who sits in seat 3?" Unanswerable. The swap is live. Leave it.
- Q2 (Partial): "Who sits at the left end?" The end seats locked early. Answer it.
- Q3 (Partial): "How many people sit between the two oldest?" Both oldest are fixed. Count is stable. Answer it.
- Q4 (Full): "What is the complete left-to-right order?" The seat 3 and seat 5 tie is still live, so the full order will not resolve. Leave it.
Marbles across four boxes, the total resolves before the split does
Four boxes hold a known total of marbles under several inequality constraints. You establish that Box A holds the most and Box D the least, and you fix the total each pair must satisfy. But the exact split between Box B and Box C never settles in your remaining time.
- Q1 (Partial): "What is the maximum marbles in Box A?" The upper bound is forced by the constraints. Answer it.
- Q2 (Partial): "Can Box D hold exactly 4?" One quick case check settles yes or no. Answer it.
- Q3 (Full): "Exact count in each box?" Needs the B-C split. Leave it.
A round-robin where two results stay undetermined
Five teams play a round-robin. You fill most of the results table from the points and the head-to-head clues. Two matches remain ambiguous because the points allow two valid outcomes, and you cannot rule either out fast.
- Q1 (Partial): "Which team finished first?" The top team's points are uniquely highest. Answer it.
- Q2 (Partial): "How many matches ended in a draw?" The draw count is fixed by the points total. Answer it.
- Q3 (Full): "What was the result of the B vs C match?" That is one of the two ambiguous cells. Leave it.
The pattern across all three is the same. The ambiguity that blocks the full solution is usually confined to a small region of the grid, and only the full-dependent questions touch that region. Everything outside it is fair game. To make this automatic, work through mixed-difficulty sets in the Optima Learn practice question bank and force yourself to extract before the set resolves.
The common trap to avoid
Partial solving fails when you blur the line between a locked deduction and a likely one. The discipline is strict: you answer a question only when the specific deduction it needs is certain, not when it feels probable.
- The mistake: Seat 3 has two candidates and one "feels" more likely from the pattern, so you pick it. That is a guess wearing the costume of a deduction. At -1, it eats the marks your real extractions earned.
- The tell: If you cannot point to the exact clue that forces the answer, it is not locked. A real partial answer has a clue you can name behind it.
- The fix: Keep full-dependent questions blank unless the grid actually resolves. Two certain marks beat three uncertain ones every time the negative marking is counted.
This is why the tagging step matters so much. The F next to a question is a reminder not to touch it from a partial state. Speed without this discipline just converts your stuck sets into negative scores, which is worse than leaving them blank. The companion piece on the 30-second DILR answer check gives you a fast way to confirm a partial answer is genuinely locked before you commit it.
Building the routine into mocks
Partial extraction is a skill you train, not a trick you read once. Set a hard cap on every practice set, around 9 to 10 minutes on a 12-minute set. When you hit the cap without a full solve, switch modes deliberately: stop solving, scan your P-tagged questions, confirm which deductions are locked, answer those, and leave. Log how many marks you recovered from sets you could not finish. That single number tracks the skill better than your overall accuracy does.
The faster you reach a stable partial state, the more of these extractions you can run, which is why working on cutting your per-set DILR time from 18 to 12 minutes pays off directly here. Speed buys the buffer to attempt a fourth set, and partial solving makes sure even a half-cracked fourth set adds to your score. Together they turn the DILR section from a set-selection gamble into a controlled exercise, and you can see the full paper structure on the CAT exam pattern page.
Before solving: Read all four questions, tag each F (needs full solution) or P (partial-eligible). Costs 40 seconds.
While solving: Chase the deductions that open up your P questions first. Those are the marks you keep.
At the cap (9-10 min): Stop solving, switch to extracting. Answer every P question whose deduction is locked.
Never: Answer an F question from a partial state. A named clue must force it, or it stays blank.
What aspirants ask about partial DILR solving
Can you really score from a DILR set you can't fully solve?
Yes, on most sets. The four questions in a set are not equally dependent on the full grid. Some ask for a single cell, a count, a maximum, or a yes/no that becomes fixed once you have 60 to 70 percent of the deductions. If you reach a stable partial state and stop guessing blindly, you can usually lock 1 to 2 questions with certainty even when the complete arrangement never resolves. The trick is to identify those questions before you commit time, not after the clock has run out.
How do I know which DILR questions need the full solution?
Read all four questions before you start solving and tag each one. Questions that ask for a complete ranking, an exact value for every entity, or who is in a specific seat usually need the full arrangement. Questions that ask for a minimum, a maximum, a count, who cannot be in a position, or a single constrained value are often answerable from partial deductions. Spend 40 seconds on this scan. It tells you where the recoverable marks sit if the set turns out to be hard.
Is partial deduction worth the negative marking risk in CAT?
Partial deduction is not guessing, so the negative marking calculation is different. You only answer a partial-eligible question once the relevant deduction is certain, even if the rest of the grid is open. A locked deduction has the same reliability as a fully solved one for that specific question. Blind guessing on a four-option MCQ carries a real penalty at -1, so you avoid it. The 2 marks you take from a stuck set come from certainty, not from probability.
When should I stop trying to fully solve a DILR set?
Set a hard cap, usually around 9 to 10 minutes on a 12-minute set. When you hit it without a full solution, switch from solving to extracting. Look at your partial-eligible questions, confirm which deductions are locked, answer those, and leave. Do not keep pushing for the complete arrangement when two marks are already sitting on the table. The most expensive mistake is spending the last 3 minutes chasing a full solve and walking away with zero.
Train partial extraction with a structured DILR plan
A strategy session with an Optima Learn mentor maps your DILR sets to your real mock data, shows where you leave recoverable marks blank, and builds the tagging and extraction routine into your prep.
Book a Free CAT Strategy CallA stuck set is not a lost set. Once you read the four questions for dependency before you solve, a half-cracked grid stops being a zero and starts being a reliable +6. Build the tag-then-extract habit across your next ten mocks and watch how many marks you were quietly throwing away. For the full DILR series and more CAT preparation guides, browse the complete set of CAT 2026 preparation resources and keep sharpening the parts of the section that cost you the most.
Solve real CAT DILR sets timed
Hand-picked LR puzzles and DI caselets with timer + solution breakdown.