DILR Answer Verification: The 30-Second CAT Recheck
A practical fix for marks lost on DILR sets you actually solve correctly. It lays out a 30-second verification protocol (re-read the stem, test the two tightest constraints, check set consistency), names the three confident-wrong-answer patterns (quantifier misread, constraint inversion, off-by-one position), and gives a two-pass drill to make the check a reflex.
A large share of lost DILR marks do not come from sets you could not solve. They come from sets you solved and then answered wrong. You built the grid, you placed everyone correctly, and then you marked an option that does not match the question that was actually asked. The arrangement was right. The reading was wrong. This is the most frustrating way to lose a mark in the CAT exam, because the work was done and the score does not show it. DILR answer verification is the fix, and it costs about 30 seconds per question.
This guide gives you a fixed verification protocol, the three confident-wrong-answer patterns it catches, and a drill to build the habit before CAT 2026.
See how cutting these silent DILR errors changes your projected percentile.
Predict My PercentileThe hidden cost of a solved-but-wrong set
Picture a 4-question seating set you crack in 11 minutes. The grid is correct. Then you mark two answers from a misread stem and one from an off-by-one count. You walk away believing you scored 4 marks. You scored 1, and two of the wrong ones carried a negative penalty. The set that should have been your best return becomes your worst.
This is why solved-but-wrong is more dangerous than unsolved. An unsolved set you skip costs you 0 and you know it is gone. A solved-but-wrong set feels like a win in the hall, so you never go back to it, and it quietly drains 3 to 4 marks plus penalties. On a section where the difference between a 90 and a 95 percentile is often four or five marks, one of these per slot is the whole gap.
The cause is structural, not careless. You read each stem once, at speed, while your working memory is full of the arrangement you just built. Under that load, exactly reads as at least, taller flips to shorter, and the third slot reads as the fourth. None of this is a logic failure. It is a reading failure that happens after the logic is done. If your solving itself is slow and that pressure is forcing the rushed reads, the companion guide on cutting a set from 18 to 12 minutes frees up the time the check needs.
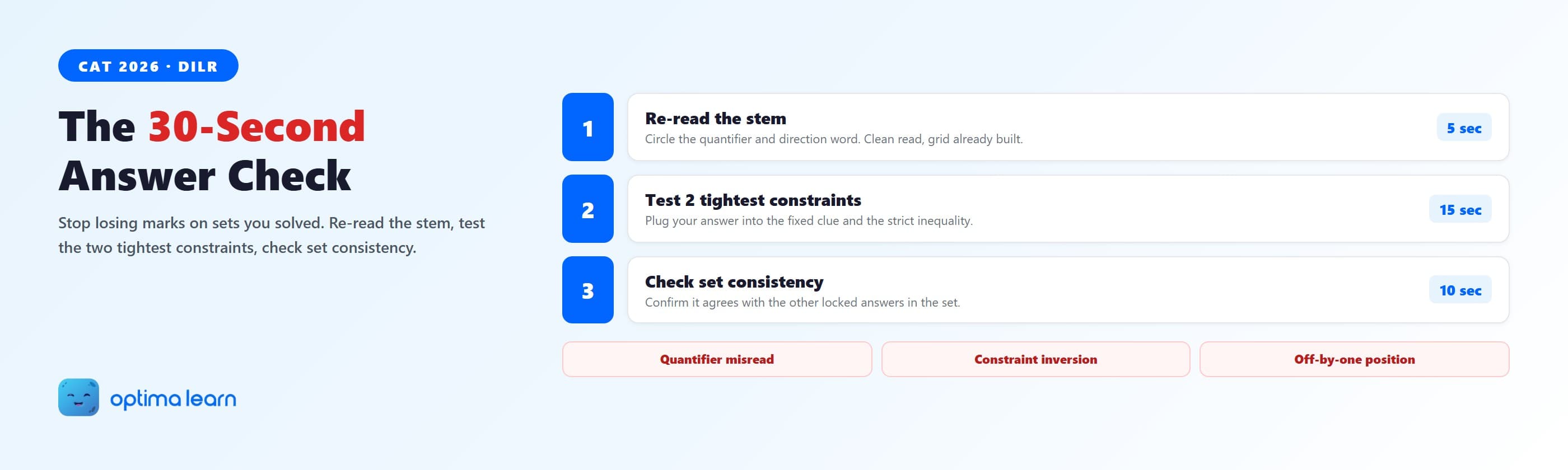
The 30-second DILR answer verification protocol
The check is three moves, run in order, on every answer before you mark it. Done at speed, it fits in 30 seconds. The point is to look at the question again with the grid already finished, because that is when a misreading becomes visible.
Run the three moves in that order because each catches a different failure. Step 1 catches the misread. Step 2 catches a wrong arrangement. Step 3 catches a slip you made on one specific question while the grid itself is fine. Skip none of them on the answers you feel sure about, because that is exactly where the silent errors live.
The 3 confident-wrong-answer patterns
Almost every solved-but-wrong answer fits one of three patterns. Learn to spot them by name and the 30-second check becomes faster, because you know what you are hunting for. The pattern that catches you most is usually stable across mocks, so track which one shows up in your error log and front-load the check toward it.
| Pattern | What it looks like | The 30-second catch |
|---|---|---|
| Quantifier misread | You read "exactly 3" as "at least 3", or "at most 2" as "exactly 2". The set has more valid cases than you counted, or fewer, and your answer fits the wrong one. | Step 1 circles the quantifier. Say it out loud in your head: "exactly three, not three or more." The mismatch shows up the instant you re-read it clean. |
| Constraint inversion | "A finishes before B" gets built as "A finishes after B". One reversed clue flips half the grid, so the arrangement is internally consistent but mirror-imaged. | Step 2 tests against the tightest inequality. Plug your answer in and read the direction word again. An inverted clue fails the test immediately. |
| Off-by-one position | You count "third from the left" from the right, or read slot 4 as slot 5. The grid is correct; you pulled the value from the neighbouring cell. | Step 3 cross-checks against your other locked answers. Point at the cell and count from the stated end out loud before you read the value. |
Notice that none of these is a solving mistake. In all three, the arrangement on your page is correct. That is what makes them invisible without a deliberate check: you have no felt sense of doubt, because the part you can feel, the logic, worked. The companion guide on pulling marks from a stuck set handles the other side of the score, where the grid is incomplete and you still want the answerable questions.
When the check flags an error, label it: quantifier, inversion, or position. Logging the name turns a vague "I should be careful" into a specific habit your brain can target. After 20 logged catches, most aspirants find one pattern accounts for over half their silent errors, and the check tightens around it.
A verification drill that builds the habit
The protocol only works if it is automatic on exam day, and that needs reps, not intentions. Build the habit with a separation drill: solve and verify as two distinct passes, so the check stops feeling like an interruption to solving and becomes its own step.
Take any 4-question DILR set from your practice bank and run it like this:
- Pass 1, solve only: Build the grid and write your four answers in pencil. Do not check anything. Move at your normal solving speed.
- Pass 2, verify only: Now run the 30-second protocol on each answer. Re-read each stem, test the two tightest constraints, check set consistency. Use a different colour pen for anything you change.
- Log every change: For each answer you flipped, write the pattern name (quantifier, inversion, position) and which step caught it. This is your error log.
- Review the colour: Count the second-colour marks across 10 sets. That count is the marks the check just saved you. It is also your honest baseline for how often you answer wrong on sets you solved right.
Run the drill on 10 sets and the protocol stops being a checklist you remember and becomes a reflex you run. You can pull fresh, filtered sets for this from the Optima Learn practice questions bank, and if you want a structured stack to drill on, the guide to building a free DILR practice set bank walks through assembling sets by type so you can isolate the arrangement formats where your misreads cluster.
Fitting the check into a timed set
Verification is worthless if it makes you slower than your set budget allows, so it has to live inside your existing time, not on top of it. The fix is to fold the check into how you mark, not bolt it on at the end.
Mark each answer the moment you finish verifying it, rather than solving all four and then verifying all four in a rushed final minute. A batch check at the end always gets squeezed when the clock runs down, and the squeeze hits the answers you were least sure about. An inline check, one question at a time, survives time pressure because each answer is already confirmed before you move on.
Step 1 (5 sec): Re-read the stem clean. Circle the quantifier and the direction word.
Step 2 (15 sec): Plug your answer into the two tightest constraints. If either breaks, fix before marking.
Step 3 (10 sec): Confirm the answer agrees with the other locked answers in the set.
Hunt for: quantifier misread, constraint inversion, off-by-one position. Mark inline, never batch at the end.
One more rule: never verify against the same reading that produced the answer. If you re-read the stem the same fast way you read it the first time, you will reproduce the same misread and feel confirmed. Read it slower, word by word, and let the grid do the arguing. The grid is the one thing you can trust, because you built it from all the clues at once.
Common doubts about checking DILR answers
How long should answer verification take in CAT DILR?
Aim for about 30 seconds per question. The check has three parts that move fast: re-read the stem (5 seconds), test your answer against the two most restrictive constraints (15 seconds), and confirm it agrees with the other answers in the same set (10 seconds). Across a 4-question set that is roughly 2 minutes on top of solving. If a set already takes 12 minutes, budget the check into that total. It is cheap insurance against losing 3 marks on a set you solved correctly.
Why do I get DILR answers wrong even when I solve the set correctly?
Most confident-wrong answers come from three patterns, none of them solving errors. You misread the quantifier (exactly read as at least), you invert a constraint (taller built as shorter), or you make an off-by-one position error (the third slot read as the fourth). Your arrangement is right. The answer you marked does not match the question that was asked. Verification catches all three, because it re-reads the stem after the grid is built, when the misreading is finally visible.
Should I verify every DILR answer or only the ones I am unsure about?
Verify every answer, including the ones you feel certain about. Confident-wrong answers feel exactly as certain as confident-right ones, which is the whole problem. The questions you breeze through are where misreads hide, because you read the stem once, fast, and trusted your first parse. The 30-second check is most valuable on the answers you would otherwise skip. Save longer re-solving only for answers that actually fail the check.
What are the two most restrictive constraints I should check against?
The most restrictive constraints eliminate the most possibilities. A fixed assignment (Person C is always in slot 2) and a strict inequality with a number (at least 3 of the 5 are on the morning shift) usually constrain a set the hardest. Words like exactly, only, and all also signal high-restriction clues. Skip the soft ones. Find the two tightest, plug your answer in, and see if anything breaks. If it violates either, you found the error before it cost you a mark.
Find the error pattern that is costing you marks
A strategy session with an Optima Learn mentor reads your actual mock data, identifies which confident-wrong-answer pattern shows up most in your DILR sets, and calibrates the 30-second check to your specific weak spot.
Book a Free CAT Strategy CallStart tracking solved-but-wrong as its own error category in your next mock, separate from sets you could not crack. Once you can see how many marks leak from sets you actually solved, the 30-second check stops being optional. For the full set of CAT preparation guides on DILR, the series covers solving speed, partial solving, set selection, and the practice infrastructure you need to make every solved set actually count toward your CAT 2026 score.
Solve real CAT DILR sets timed
Hand-picked LR puzzles and DI caselets with timer + solution breakdown.